 PostGIS
PostGIS Mobile
Mobile QGIS
QGIS MapBender
MapBender GeoServer
GeoServer GeoNode
GeoNode GeoNetwork
GeoNetwork Solutions
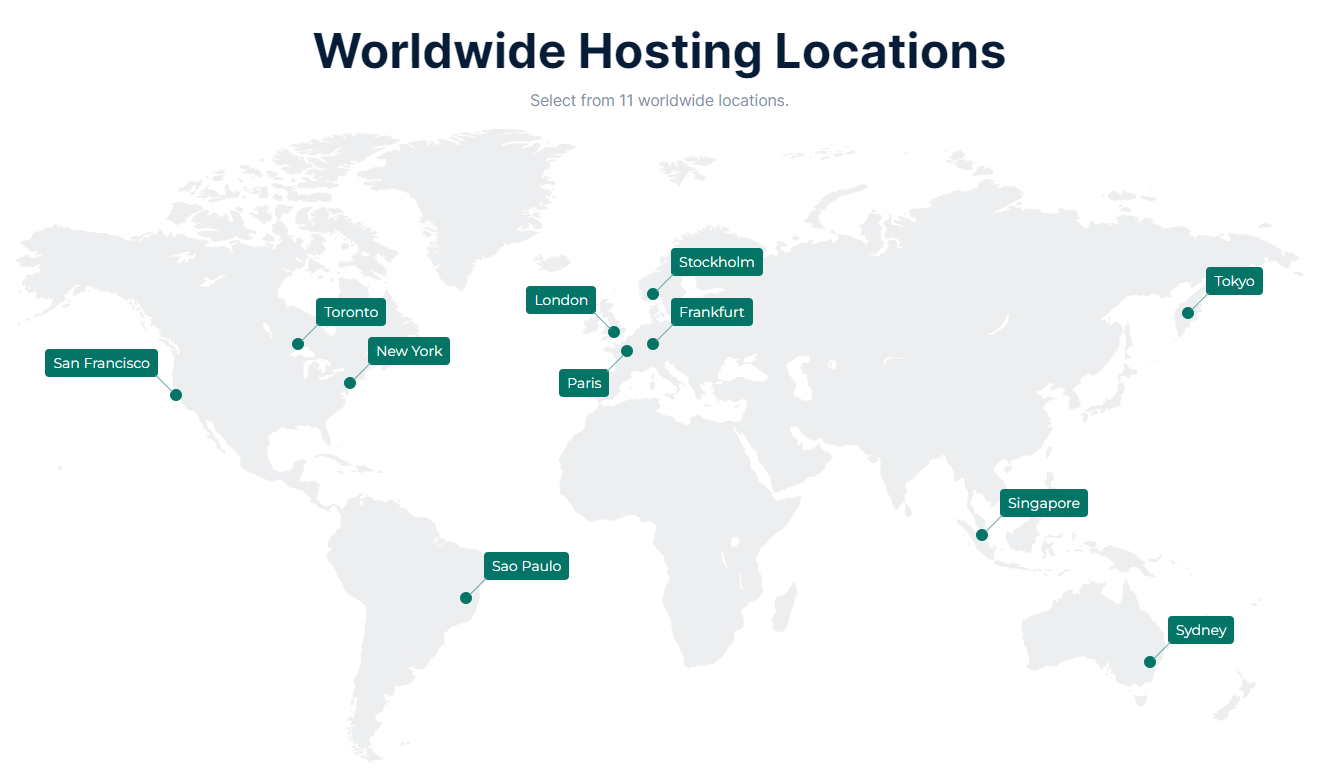
Solutions



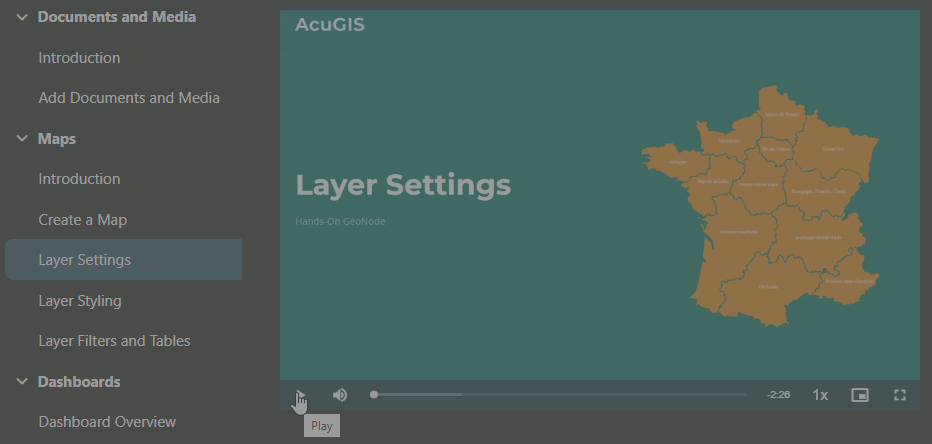
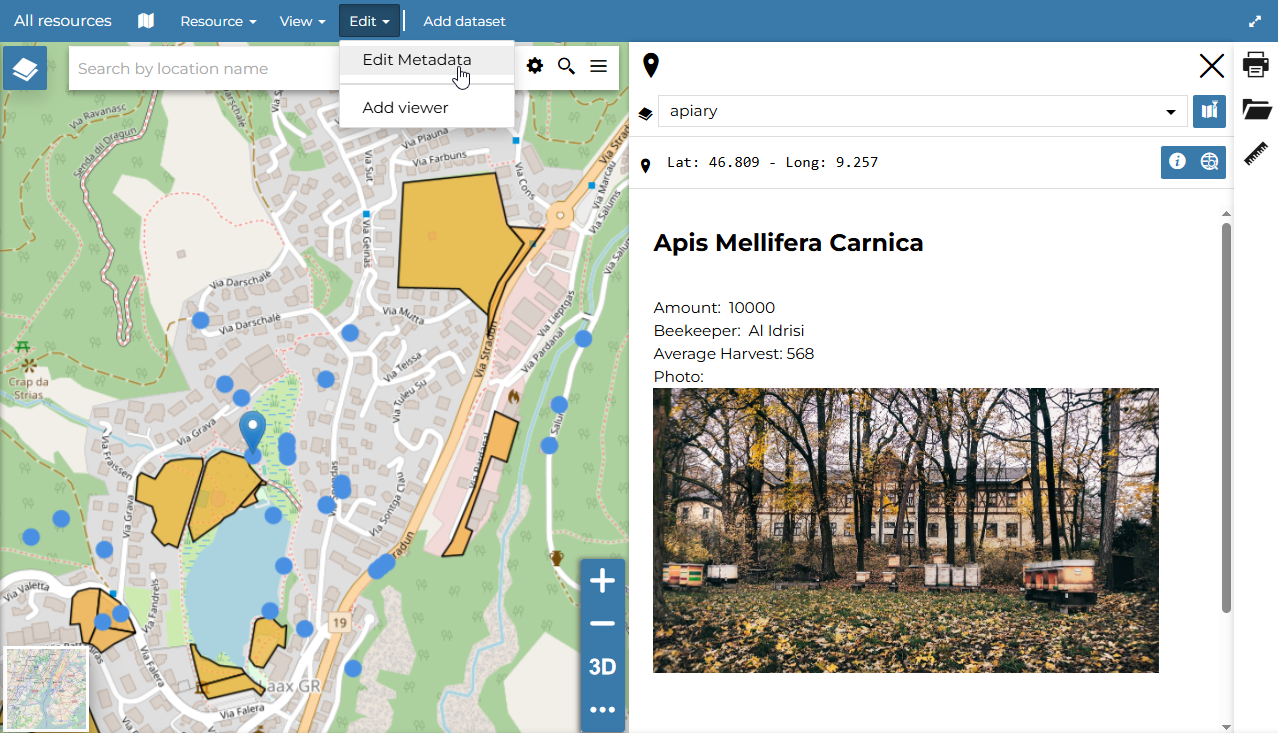
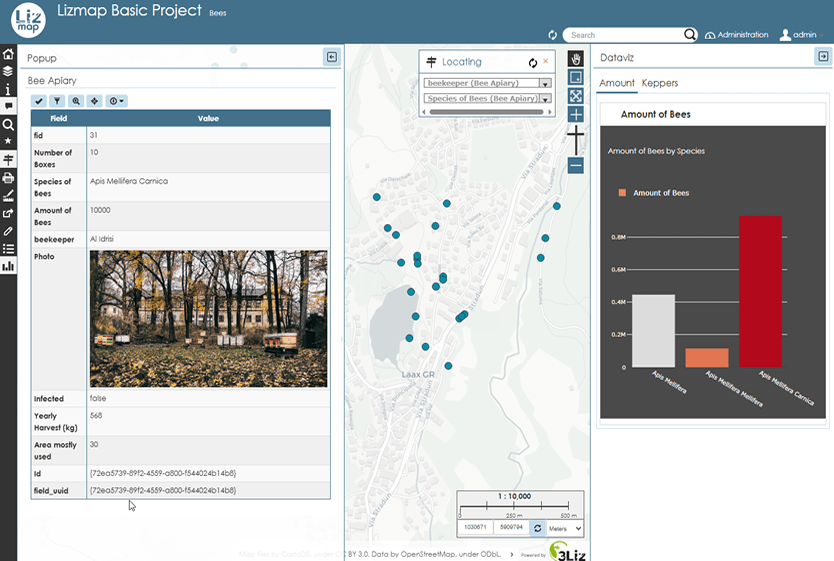








70 lines
1.3 KiB
Markdown
70 lines
1.3 KiB
Markdown
# Clustering
|
|
|
|
Group features based on spatial proximity using clustering algorithms.
|
|
|
|
## Overview
|
|
|
|
Clustering groups nearby features into clusters, identifying spatial patterns and groupings in point data.
|
|
|
|
## Inputs
|
|
|
|
- **Dataset**: Point dataset
|
|
- **Method**: Clustering algorithm
|
|
- **Parameters**: Algorithm-specific parameters
|
|
|
|
## Outputs
|
|
|
|
New dataset containing:
|
|
|
|
- Original features
|
|
- **Cluster ID**: Assigned cluster identifier
|
|
- **Cluster Size**: Number of features in cluster
|
|
- Original attributes
|
|
|
|
## Algorithms
|
|
|
|
### K-Means Clustering
|
|
|
|
Groups points into k clusters by minimizing within-cluster variance.
|
|
|
|
### DBSCAN
|
|
|
|
Density-based clustering that identifies clusters of varying shapes.
|
|
|
|
### Hierarchical Clustering
|
|
|
|
Builds cluster hierarchy using distance measures.
|
|
|
|
## Example
|
|
|
|
```json
|
|
{
|
|
"dataset_id": 123,
|
|
"method": "kmeans",
|
|
"k": 5
|
|
}
|
|
```
|
|
|
|
## Background Jobs
|
|
|
|
This analysis runs as a background job.
|
|
|
|
## Use Cases
|
|
|
|
- Market segmentation
|
|
- Service area identification
|
|
- Pattern recognition
|
|
- Data exploration
|
|
|
|
## Notes
|
|
|
|
- Algorithm selection depends on data characteristics
|
|
- Parameter tuning affects results
|
|
- Results may vary with different random seeds
|
|
- Consider spatial scale when interpreting clusters
|
|
|
|
## Related Documentation
|
|
|
|
- [Analysis API](../api/analysis.md)
|
|
|
